
在WWDC的Advanced Graphics and Animations for iOS Apps(WWDC14 419,关于UIKit和Core Animation基础的session在早年的WWDC中比较多)中有这样一张图:
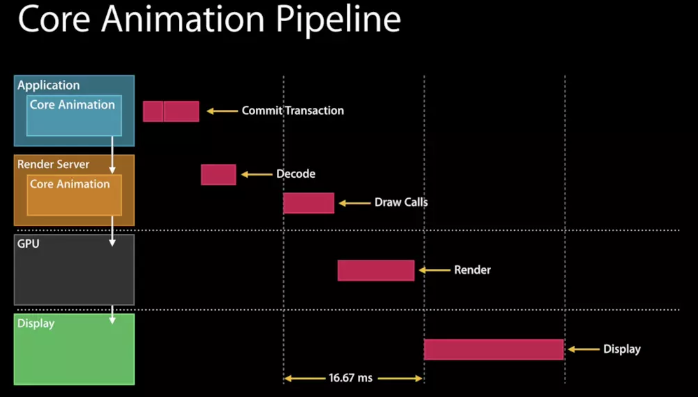
我们可以看到,在Application这一层中主要是CPU在操作,而到了Render Server这一层,CoreAnimation会将具体操作转换成发送给GPU的draw calls(以前是call OpenGL ES,现在慢慢转到了Metal),显然CPU和GPU双方同处于一个流水线中,协作完成整个渲染工作。
如果要在显示屏上显示内容,我们至少需要一块与屏幕像素数据量一样大的frame buffer,作为像素数据存储区域,而这也是GPU存储渲染结果的地方。如果有时因为面临一些限制,无法把渲染结果直接写入frame buffer,而是先暂存在另外的内存区域,之后再写入frame buffer,那么这个过程被称之为离屏渲染。

大家知道,如果我们在UIView中实现了drawRect方法,就算它的函数体内部实际没有代码,系统也会为这个view申请一块内存区域,等待CoreGraphics可能的绘画操作。
对于类似这种“新开一块CGContext来画图“的操作,有很多文章和视频也称之为“离屏渲染”(因为像素数据是暂时存入了CGContext,而不是直接到了frame buffer)。进一步来说,其实所有CPU进行的光栅化操作(如文字渲染、图片解码),都无法直接绘制到由GPU掌管的frame buffer,只能暂时先放在另一块内存之中,说起来都属于“离屏渲染”。
自然我们会认为,因为CPU不擅长做这件事,所以我们需要尽量避免它,就误以为这就是需要避免离屏渲染的原因。但是根据苹果工程师的说法,CPU渲染并非真正意义上的离屏渲染。另一个证据是,如果你的view实现了drawRect,此时打开Xcode调试的“Color offscreen rendered yellow”开关,你会发现这片区域不会被标记为黄色,说明Xcode并不认为这属于离屏渲染。
其实通过CPU渲染就是俗称的“软件渲染”,而真正的离屏渲染发生在GPU。
在上面的渲染流水线示意图中我们可以看到,主要的渲染操作都是由CoreAnimation的Render Server模块,通过调用显卡驱动所提供的OpenGL/Metal接口来执行的。通常对于每一层layer,Render Server会遵循“画家算法”,按次序输出到frame buffer,后一层覆盖前一层,就能得到最终的显示结果(值得一提的是,与一般桌面架构不同,在iOS中,设备主存和GPU的显存共享物理内存,这样可以省去一些数据传输开销)。

然而有些场景并没有那么简单。作为“画家”的GPU虽然可以一层一层往画布上进行输出,但是无法在某一层渲染完成之后,再回过头来擦除/改变其中的某个部分——因为在这一层之前的若干层layer像素数据,已经在渲染中被永久覆盖了。这就意味着,对于每一层layer,要么能找到一种通过单次遍历就能完成渲染的算法,要么就不得不另开一块内存,借助这个临时中转区域来完成一些更复杂的、多次的修改/剪裁操作。
如果要绘制一个带有圆角并剪切圆角以外内容的容器,就会触发离屏渲染。我的猜想是(如果读者中有图形学专家希望能指正):
此时我们就不得不开辟一块独立于frame buffer的空白内存,先把容器以及其所有子layer依次画好,然后把四个角“剪”成圆形,再把结果画到frame buffer中。这就是GPU的离屏渲染。
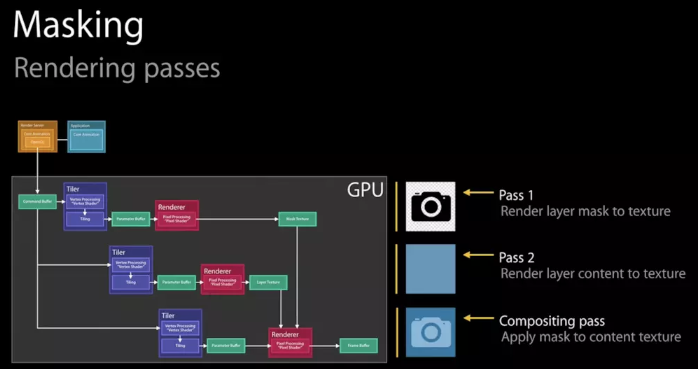

GPU的操作是高度流水线化的。本来所有计算工作都在有条不紊地正在向frame buffer输出,此时突然收到指令,需要输出到另一块内存,那么流水线中正在进行的一切都不得不被丢弃,切换到只能服务于我们当前的“切圆角”操作。等到完成以后再次清空,再回到向frame buffer输出的正常流程。
在tableView或者collectionView中,滚动的每一帧变化都会触发每个cell的重新绘制,因此一旦存在离屏渲染,上面提到的上下文切换就会每秒发生60次,并且很可能每一帧有几十张的图片要求这么做,对于GPU的性能冲击可想而知(GPU非常擅长大规模并行计算,但是我想频繁的上下文切换显然不在其设计考量之中)
尽管离屏渲染开销很大,但是当我们无法避免它的时候,可以想办法把性能影响降到最低。优化思路也很简单:既然已经花了不少精力把图片裁出了圆角,如果我能把结果缓存下来,那么下一帧渲染就可以复用这个成果,不需要再重新画一遍了。
CALayer为这个方案提供了对应的解法:shouldRasterize。一旦被设置为true,Render Server就会强制把layer的渲染结果(包括其子layer,以及圆角、阴影、group opacity等等)保存在一块内存中,这样一来在下一帧仍然可以被复用,而不会再次触发离屏渲染。有几个需要注意的点:
渲染性能的调优,其实始终是在做一件事:平衡CPU和GPU的负载,让他们尽量做各自最擅长的工作。

绝大多数情况下,得益于GPU针对图形处理的优化,我们都会倾向于让GPU来完成渲染任务,而给CPU留出足够时间处理各种各样复杂的App逻辑。为此Core Animation做了大量的工作,尽量把渲染工作转换成适合GPU处理的形式(也就是所谓的硬件加速,如layer composition,设置backgroundColor等等)。
但是对于一些情况,如文字(CoreText使用CoreGraphics渲染)和图片(ImageIO)渲染,由于GPU并不擅长做这些工作,不得不先由CPU来处理好以后,再把结果作为texture传给GPU。除此以外,有时候也会遇到GPU实在忙不过来的情况,而CPU相对空闲(GPU瓶颈),这时可以让CPU分担一部分工作,提高整体效率。
一个典型的例子是,我们经常会使用CoreGraphics给图片加上圆角(将图片中圆角以外的部分渲染成透明)。整个过程全部是由CPU完成的。这样一来既然我们已经得到了想要的效果,就不需要再另外给图片容器设置cornerRadius。另一个好处是,我们可以灵活地控制裁剪和缓存的时机,巧妙避开CPU和GPU最繁忙的时段,达到平滑性能波动的目的。
这里有几个需要注意的点:
由于在iOS10之后,系统的设计风格慢慢从扁平化转变成圆角卡片,即刻的设计风格也随之发生变化,加入了大量圆角与阴影效果,如果在处理上稍有不慎,就很容易触发离屏渲染。为此我们采取了以下一些措施:

离屏渲染牵涉了很多Core Animation、GPU和图形学等等方面的知识,在实践中也非常考验一个工程师排查问题的基本功、经验和判断能力——如果在不恰当的时候打开了shouldRasterize,只会弄巧成拙。
下一篇:微信小程序开发之SVG的使用










